Sequence Generation using Deep Recurrent Networks and Embedding Representations: A study case in music.
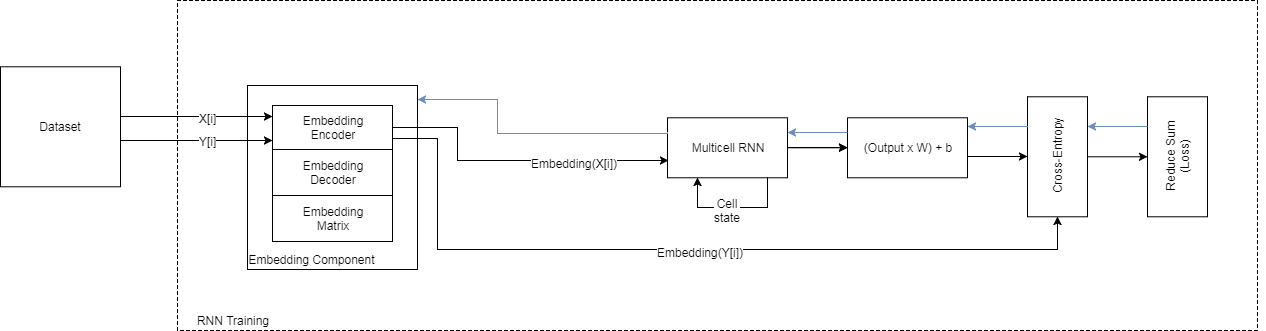
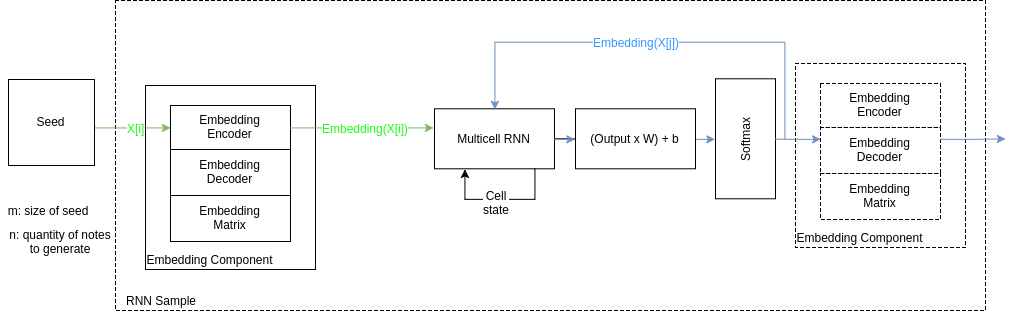
Abstract
Automatic generation of sequences has been a highly explored field in the last years. In particular, natural language processing and automatic music composition have gained importance due to the recent advances in machine learning and Neural Networks with intrinsic memory mechanisms such as Recurrent Neural Networks. This paper evaluates different types of memory mechanisms (memory cells) and analyze their performance in the field of music composition. The proposed approach considers music theory concepts such as transposition, and uses data transformations (embeddings) to introduce semantic meaning and improve the quality of the generated melodies. The performance of the proposed architecture is evaluated using quantitative metrics to measure the tonality of a musical composition.
Datasets, Model Weights and more
Code
Demos
Click the images to see a youtube video
Final models representative songs

Training evolution

Research Replication
Note: All is done assuming you are in your home directory
Set the environment
Create a root folder and clone the scripts and model repositories:
mkdir exampleresearch
cd exampleresearch
git clone https://github.com/sebasgverde/rnn-cells-music-paper.git
git clone https://github.com/sebasgverde/rnnMusicSeqGenerator
create a virtual env using the requirements in rnnMusicSeqGenerator
mkvirtualenv exampleresearchmusic
pip install -r ~/exampleresearch/rnnMusicSeqGenerator/requirements.txt
For this two special libraries which were developed by me, you have two options, I recommend to install them also in the virtual env
pip install music-geometry-eval==1.0
pip install midi-manager==1.0
but you can also clone the repositories and use them as normal packages
git clone -b 1.0 --single-branch https://github.com/sebasgverde/music-geometry-eval.git
git clone -b 1.0 --single-branch https://github.com/sebasgverde/midi-manager.git
Datasets
The mono-midi-transposition-dataset is the result of series of transformations over the mono-MusicXML-dataset
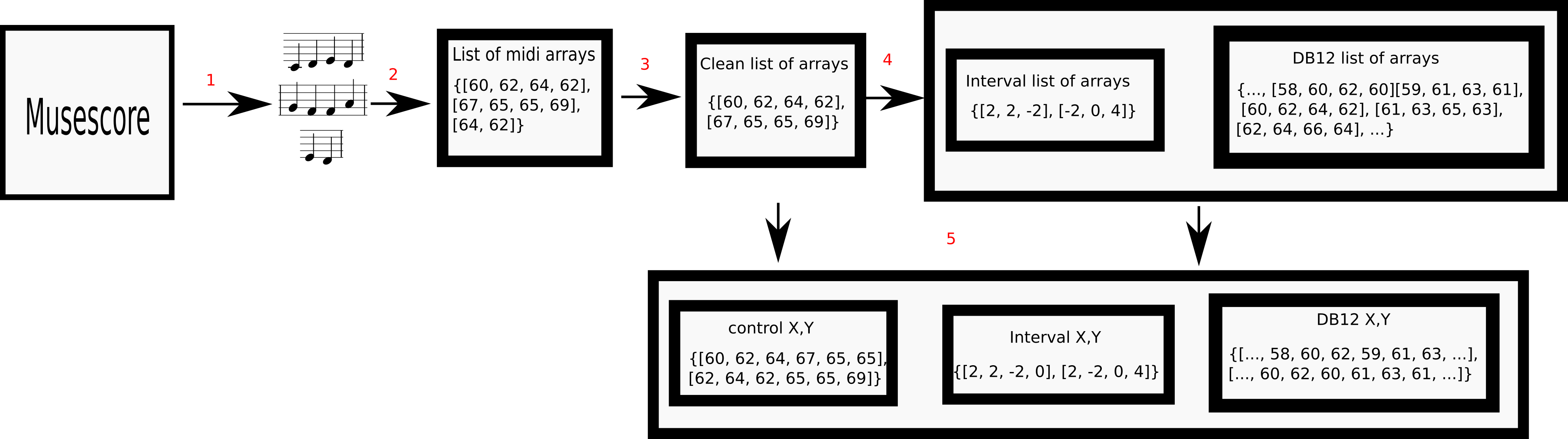 Download the datasets:
Download the datasets:
mkdir dataset
wget -N https://www.dropbox.com/sh/xyr47x5ck48krvx/AAAprJDo2at6AlEiWVp-U9cqa?dl=1 -O dataset.zip
unzip dataset.zip -d dataset/
rm dataset.zip
You can also make some unit test to the pickles
python rnn-cells-music-paper/paper_scripts/unittestdatacreation.py -v
Special Note: If instead of replicating the research you want to specifically reproduce the paper results, you can just skip the next two sections and download the network weights and the 900 generated songs.
wget -N https://www.dropbox.com/s/34w1miaz6j01rw5/models.zip?dl=1 -O model_weights.zip
unzip model_weights.zip -d ~/exampleresearch/
rm model_weights.zip
mkdir ~/exampleresearch/experiments/
wget -N https://www.dropbox.com/s/v2w18qoos8quz8c/generated100.zip?dl=1 -O generated_songs.zip
unzip generated_songs.zip -d ~/exampleresearch/experiments/
rm generated_songs.zip
Optimal number of layers
Run the script which does 45 experiments (the 3 dataset variations, with the 3 cell types and number of layers from 1 to 5), time will depend on the GPU hardware, in a Nvidia m1000 it takes around a week
./rnn-cells-music-paper/paper_scripts/bashlayerscompleteexperimet.sh
This will create the folder models, with all the models separated in folders by dataset and cell type.
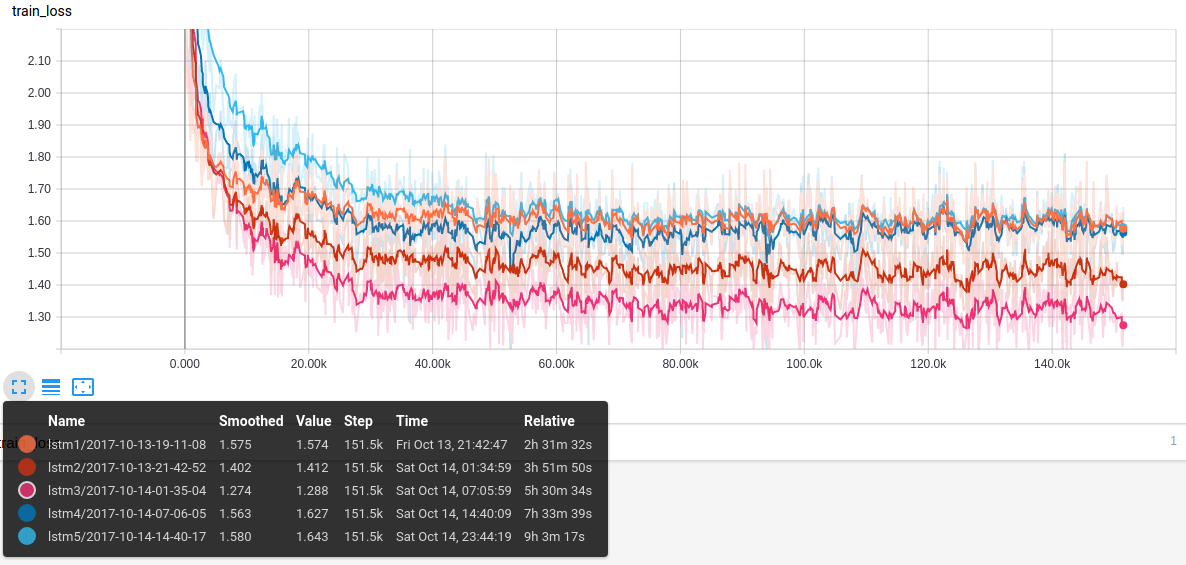
It is time now to get the learning curves graphs to reduce the research to 9 models. Use this command for each combination of dataset-cell:
tensorboard --logdir models/control/lstm/
In the “Scalars” of tensorboard you will see a graph like this:
Generating songs
Now that we have reduced the problem to 9 models (best learning curve for each pair dataset-cell), we will generate 100 songs with each model, always using the same seed and size (just modify the generate9timesn script with the appropriate layer number)
mkdir ~/exampleresearch/experiments/
mkdir ~/exampleresearch/experiments/generated
./rnn-cells-music-paper/paper_scripts/generate9timesn.sh
This will create 9 folders, each with 200 files, the 100 songs as midi and as pickle file with the song as a list.

Models metric evaluation
The next step is to use the music_geometry_eval library to test the tonality of the models. This script will apply 3 quantitative metrics (Conjunct Melody Motion, Limited Macroharmony and Centricity) to each set of 100 songs. The output file will have 9 tables with all the songs, different latex tables with summary information, the list of the most representative song of each model (the song whose metrics have the lower euclidean distance to the mean of the 100) and finally, a latex table with the mean and standard deviation for each metric in each model for each 100 song set.
python rnn-cells-music-paper/paper_scripts/eval_n_songs.py --generated_dir ~/exampleresearch/experiments/generated > ~/exampleresearch/experiments/metrics_eval_100_songs.txt
After that, create a folder and move each of the most representative songs there, this script will generate the latex code for the table with those metrics
python rnn-cells-music-paper/paper_scripts/eval_most_rep_songs.py --songs_folder ~/exampleresearch/experiments/most_repres_songs > ~/exampleresearch/experiments/metrics_eval_most_repres_songs.txt
Analysing tonality of the models quantitatively
In order to analyze it, it is necessary to have a baseline applying the metrics to the dataset:
python rnn-cells-music-paper/paper_scripts/dataset_metric_eval.py --pickles_dir ~/exampleresearch/dataset > ~/exampleresearch/experiments/metrics_eval_dataset.txt
Once you compile the latex tables, they will look like this:
Dataset

Models
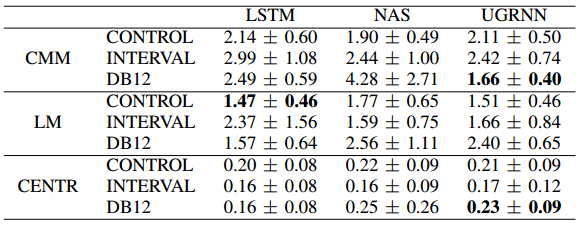
Most Representative Songs

Now, you can use the scripts in template_scripts, to transform the midi files in mp3, wav and jpg, however, the images aren’t very flexible from console, seem there’s no way to export to png from console indicating the dimensions, so I recommend:
- you can use mid_2_wav and mid_2_mp3 to get the audios
- open the midis in musescore, change the dimension in design->page settings
- save as .mscz
- export as png (even so the console doesn’t work, export each png manually)
Other scripts
The scripts in scripts_for_supercomputing are modified versions of the training script for 6 of the experiments which I trained in a cluster environment in HPC centre Apolo. It works with slurm as cluster management and job scheduling system, so also the slurm scripts are provided.
Next two experiments correspond to two different papers:
Embeddings as representation for symbolic music
Abstract
A representation technique that allows encoding music in a way that contains musical meaning would improve the results of any model trained for computer music tasks like generation of melodies and harmonies of better quality. The field of natural language processing has done a lot of work in finding a way to capture the semantic meaning of words and sentences, and word embeddings have successfully shown the capabilities for such a task. In this paper, we experiment with embeddings to represent musical notes from 3 different variations of a dataset and analyze if the model can capture useful musical patterns. To do this, the resulting embeddings are visualized in projections using the t-SNE technique.
To visualize the embeddings, we will us the tensorboard embeddings option, in the case of the paper I used the lstm models for the 3 datasets since these are the most common cells
tensorboard --logdir models/control/lstm/lstm3/
tensorboard --logdir models/interval/lstm/lstm4/
tensorboard --logdir models/db12/lstm/lstm4/
Then in tersorboard, choose a point and you will see the nearest points with Euclidean and cosine distance.

Cross entropy as objective function for music generative models
Abstract
The election of the function to optimize when training a machine learning model is very important since this is which lets the model learn. It is not trivial since there are many options, each for different purposes. In the case of sequence generation of text, cross entropy is a common option because of its capability to quantify the predictive behavior of the model. In this paper, we test the validity of cross entropy for a music generator model with an experiment that aims to correlate improvements in the loss value with the reduction of randomness and the ability to keep consistent melodies. We also analyze the relationship between these two aspects which respectively relate to short and long term memory and how they behave and are learned differently.
The validate cross-entropy as cost function, first, we will train a model varying the “save_every” parameter to have different examples of cross-entropy.
python 'rnnMusicSeqGenerator/train.py' --save_dir ~/exampleresearch/experiments/cost_function_validation --log_dir ~/exampleresearch/experiments/cost_function_validation --data_dir ~/exampleresearch/dataset/train_final_cleaned.p --num_epochs 50 --batch_size 15 --training_mode='melody' --model 'lstm' --num_layers 2 --save_every 250 --max_models_keep 10
Finally, we manually generate a song with the same seed and size for each model, for example
mkdir ~/exampleresearch/experiments/cost_function_validation/songs
python 'rnnMusicSeqGenerator/sample.py' --ckpt_dir ~/exampleresearch/experiments/cost_function_validation -n 30 --output_uri ~/exampleresearch/experiments/cost_function_validation/songs/output_controlcase_loss_4.67827-0.mid --seed '60 62 64 62' --sampling_mode='melody' --ckpt_file ~/exampleresearch/experiments/cost_function_validation/model.ckpt_loss_4.67827-0