A framework to compare music generative models using automatic evaluation metrics extended to rhythm.

Abstract
To train a machine learning model is necessary to take numerous decisions about many options for each process involved, in the field of sequence generation and more specifically of music composition, the nature of the problem helps to narrow the options but at the same time, some other options appear for specific challenges. This paper takes the framework proposed in a previous research that did not consider rhythm to make a series of design decisions, then, rhythm support is added to evaluate the performance of two RNN memory cells in the creation of monophonic music. The model considers the handling of music transposition and the framework evaluates the quality of the generated pieces using automatic quantitative metrics based on geometry which have rhythm support added as well.
Datasets, Model Weights and more
Code
Demos
Click the images to see a youtube video
Final models representative songs



Research Replication
Note: All is done assuming you are in your home directory
Set the environment
Create a root folder and clone the scripts and model repositories:
mkdir exampleresearch
cd exampleresearch
git clone https://github.com/sebasgverde/rnn-time-music-paper.git
git clone -b 1.0 --single-branch git@github.com:sebasgverde/mono_music_rnn_generator.git rnnmusic
create a virtual env using the requirements in rnnMusicSeqGenerator
mkvirtualenv exampleresearchmusic
pip install -r ~/exampleresearch/rnnmusic/requirements.txt
For this special library which was developed by me, you have two options, I recommend to install it also in the virtual env
pip install music-geometry-eval==2.0
but you can also clone the repository and use it as a normal package
git clone -b 2.0 --single-branch https://github.com/sebasgverde/music-geometry-eval.git
Datasets
The mono-midi-transposition-dataset is the result of series of transformations over the mono-MusicXML-dataset
 Download the datasets:
Download the datasets:
mkdir data
wget -N https://www.dropbox.com/s/x0delcrq2jmo79i/data.zip?dl=1 -O data.zip
unzip data.zip -d data/
rm data.zip
Special Note: If instead of replicating the research you want to specifically reproduce the paper results, you can just skip the next two sections and download the network weights and the 600 generated songs.
mkdir models/
wget -N https://www.dropbox.com/s/1gofckoiqrymsyh/selected_models.zip?dl=1 -O model_weights.zip
unzip model_weights.zip -d ~/exampleresearch/models/selected
rm model_weights.zip
mkdir ~/exampleresearch/experiments/
wget -N https://www.dropbox.com/s/n2i1wgvm2bqky5p/generated_songs.zip?dl=1 -O generated_songs.zip
unzip generated_songs.zip -d ~/exampleresearch/experiments/
rm generated_songs.zip
Optimal number of units
Run the script which does 30 experiments (the 3 dataset variations, with the 2 cell types and 5 number of units), time will depend on the GPU hardware.
./rnn-time-music-paper/train.sh
This will create the folder models, with all the models separated in folders by dataset and cell type, inside the respective folders there will be the weights and a pickle with the model hyperparameters that are necesary to use the models at sampling, also pickles with information about the training history and learning curves graphs.
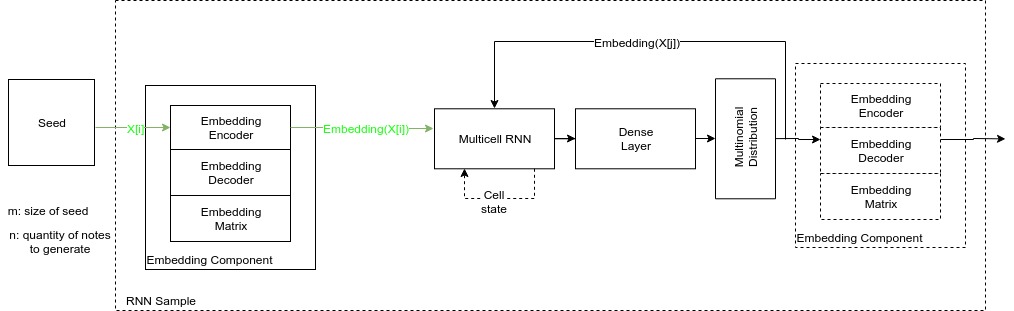
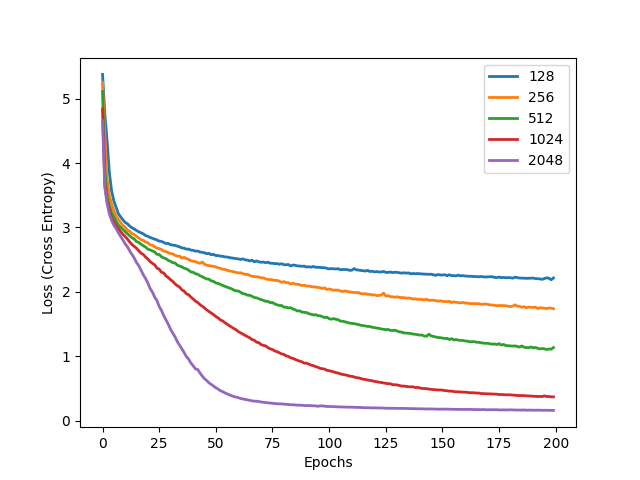
You can use the next script to create the general learning curves using the learning_curve_info pickles, which contains the learning groups for the a specific dataset, type (trianing or validation) and unit. Just open the script and modify it depending of what you need
python rnn-time-music-paper/make_learning_curves_graphic.py
You will see a graph like this:
Generating songs
Now that we have reduced the problem to 6 models (best learning curve for each pair dataset-cell), we will generate 100 songs with each model, always using the same seed and size (just modify the generatesongs script with the appropriate units number)
mkdir ~/exampleresearch/experiments/
mkdir ~/exampleresearch/experiments/generated_songs
./rnn-time-music-paper/generatesongs.sh
This will create 6 folders, each with 200 files, the 100 songs as midi and as pickle file with the song as a list.

Models metric evaluation
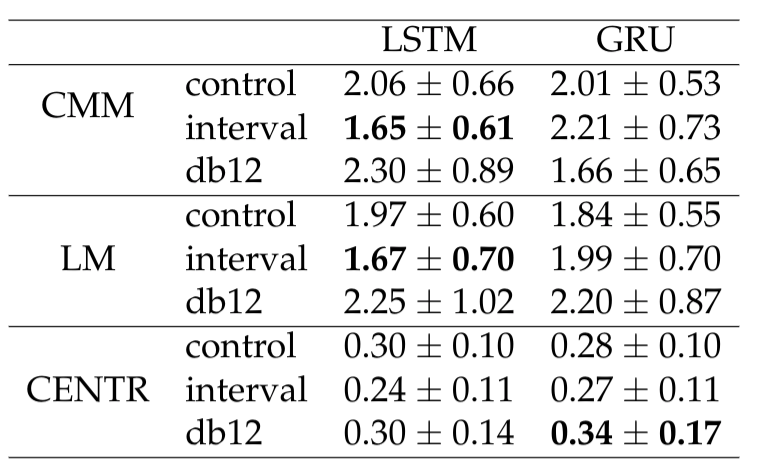
The next step is to use the music_geometry_eval library to test the tonality of the models. This script will apply 3 quantitative metrics (Conjunct Melody Motion, Limited Macroharmony and Centricity) to each set of 100 songs. The output file will have 6 tables with all the songs, different latex tables with summary information, the list of the most representative song of each model (the song whose metrics have the lower euclidean distance to the mean of the 100) and finally, a latex table with the mean and standard deviation for each metric in each model for each 100 song set.
python rnn-time-music-paper/eval_n_songs.py --generated_dir ~/exampleresearch/experiments/generated_songs > ~/exampleresearch/experiments/eval_n_songs_tables.txt
After that, create a folder and move each of the most representative songs there, this script will generate the latex code for the table with those metrics
python rnn-time-music-paper/eval_most_rep_songs.py --songs_folder ~/exampleresearch/experiments/rep_songs > ~/exampleresearch/experiments/eval_most_rep_tables.txt
Analysing tonality of the models quantitatively
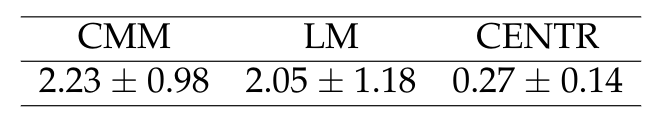
In order to analyze it, it is necessary to have a baseline applying the metrics to the dataset:
python rnn-time-music-paper/dataset_metric_eval.py --pickles_dir ~/exampleresearch/data > ~/exampleresearch/experiments/dataset_metric_eval_tables.txt
Once you compile the latex tables, they will look like this:
Dataset
Models
Most Representative Songs

Now, you can use the scripts in template_scripts, to transform the midi files in mp3, wav and jpg, however, the images aren’t very flexible from console, seem there’s no way to export to png from console indicating the dimensions, so I recommend:
- you can use mid_2_wav and mid_2_mp3 to get the audios
- open the midis in musescore, change the dimension in design->page settings
- save as .mscz
- export as png (even so the console doesn’t work, export each png manually)